Data Analysis and System Performance
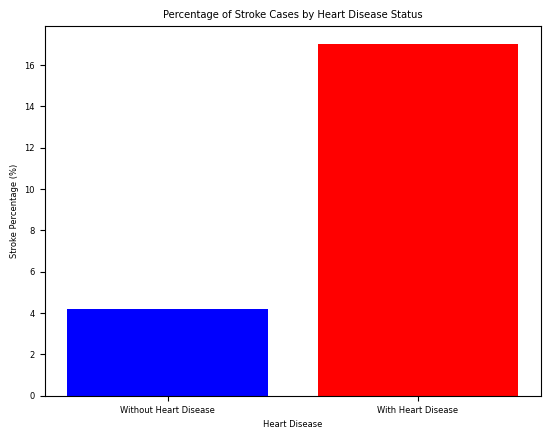
Graph 1 Percentage of Stroke Cases by Heart Disease Status:
Separates the patients who had strokes and had heart versus patients with and without heart disease.
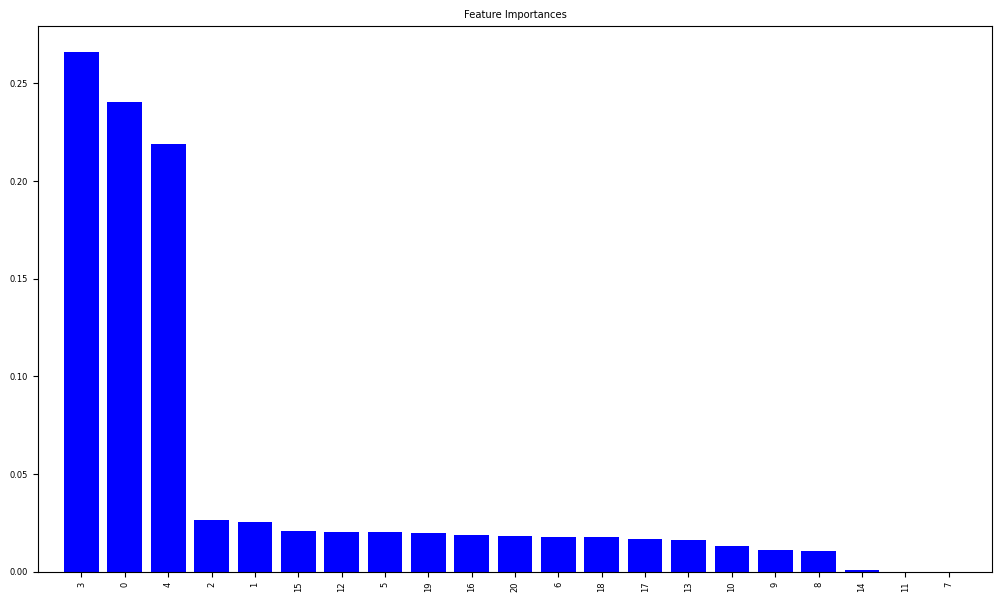
Graph 2 Feature Importance:
Shows the highest to lowest correlated features. The top three are average glucose level, BMI, and age.
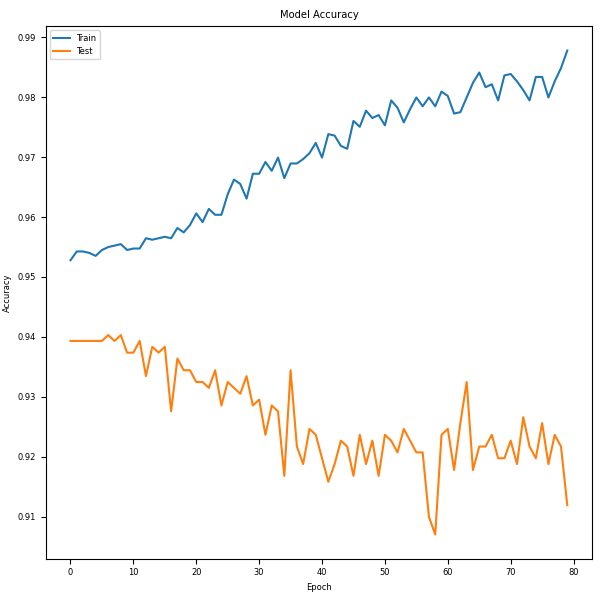
Graph 3 Model Accuracy:
Model accuracy for our Neural Network model. The blue line is training data and the orange line is testing data. The x-axis represents epochs (complete passes through the dataset), and the y-axis represents accuracy (0–1 or 0–100%).
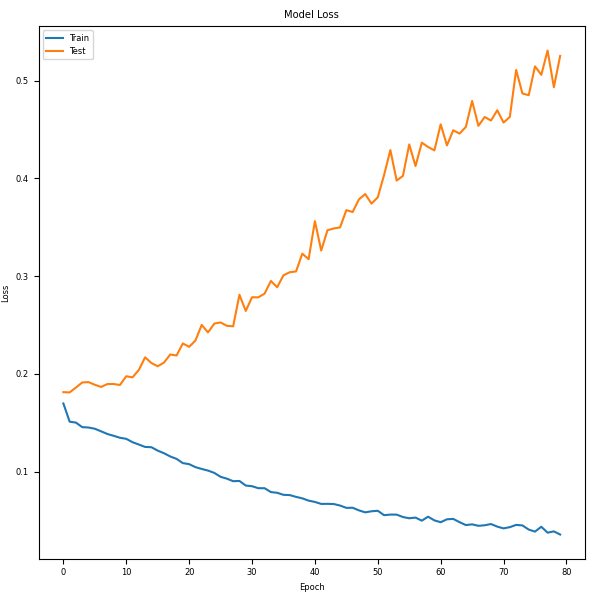
Graph 4 Model Loss:
Model loss provides insights into training dynamics and convergence. Like the accuracy graph, the x-axis represents epochs and the y-axis represents the loss value. We used 192 neurons and 4 layers.